Understand Domain
Decisions are not made in a vacuum. Causal inference, decision theory, and software systems only create value when tailored to the domain in which real decisions are made. Domain knowledge shapes which questions are meaningful, which signals are trustworthy, which constraints are binding, and which mistakes are costly. Without it, even technically correct analyses can lead to irrelevant conclusions or harmful decisions.
Product data improvements
We study the problem of improving product data quality at scale. Rather than treating causal inference, decision theory, or software systems in the abstract, the course anchors these ideas in a real operational setting.
The course is grounded in challenges observed in large-scale generative AI systems operating in production. In such systems, AI generates vast numbers of potential changes to product data, creating a quality-control problem that cannot be solved through manual review or intuition alone. Determining which changes will resonate with shoppers, measuring their business impact, and using those insights to guide future product data improvements require systematic learning loops that connect evidence to action.
A concrete way to grasp this domain is to look at a real product page, such as Keurig K-Express Single Serve Coffee Maker on Amazon. What shoppers see as a simple product listing belies a rich set of underlying data decisions—the title, structured attributes, images, pricing context, badges, and descriptive text that shape whether shoppers can find, understand, and trust what they’re buying. When an AI system modifies any of these elements at scale, each change is motivated by a hypothesis about what will resonate with shoppers—hypotheses that must be tested and measured to determine what actually drives business outcomes.
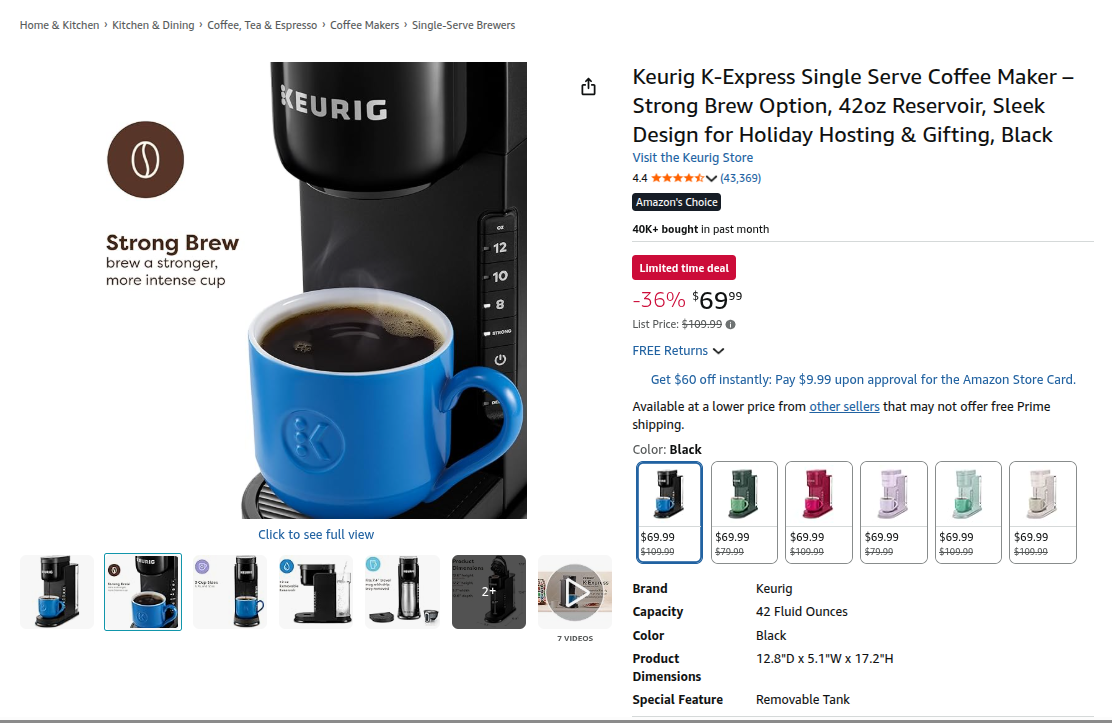
Product Data
To explore these challenges in a controlled setting, we first introduce a simulation tool that generates realistic retail data with known ground truth, then showcase an AI system that creates the kind of quality-control problem motivating the rest of the course.
Online Retail Simulator
We introduce the  Online Retail Simulator as a simulation tool that generates realistic product catalogs, shopper behavior, and sales transactions with known ground truth. This section explores how treatment effects can be injected and measured within this controlled environment, enabling validation of causal inference methods before applying them to real-world data. The goal is to establish a realistic testing ground where hypotheses about product data quality can be measured against observable outcomes across the conversion funnel.
Online Retail Simulator as a simulation tool that generates realistic product catalogs, shopper behavior, and sales transactions with known ground truth. This section explores how treatment effects can be injected and measured within this controlled environment, enabling validation of causal inference methods before applying them to real-world data. The goal is to establish a realistic testing ground where hypotheses about product data quality can be measured against observable outcomes across the conversion funnel.
Catalog AI
We introduce Catalog AI as a generative AI system for creating product content at scale using large language models to generate descriptions and metadata. This section examines how AI-generated content creates a quality-control problem that requires causal measurement, where each generated change represents a hypothesis about what will improve shopper experience and conversion. The goal is to connect content generation to treatment effect heterogeneity and establish systematic evaluation methods for AI-produced catalog improvements, as discussed in Addressing Gen AI’s Quality Control Problem (Harvard Business Review).