Download the notebook here!
Interactive online version: ![]()
Potential Outcomes Model
Reference: Causal Inference: The Mixtape, Chapter 4: Potential Outcomes Causal Model (pp. 119-174)
This lecture introduces the potential outcome framework for causal inference. We apply these concepts using the Online Retail Simulator to answer: What would be the effect on sales if we improved product content quality?
Part I: Theory
This section covers the theoretical foundations of the potential outcome framework as presented in Cunningham’s Causal Inference: The Mixtape, Chapter 4.
1. The potential outcome framework
The potential outcome framework, also known as the Rubin Causal Model (RCM), provides a precise mathematical language for defining causal effects. The framework was developed by Donald Rubin in the 1970s, building on earlier work by Jerzy Neyman.
Core definitions
For each unit \(i\) in a population, we define:
\(D_i \in \{0, 1\}\): Treatment indicator (1 if unit receives treatment, 0 otherwise)
\(Y_i^1\): Potential outcome under treatment — the outcome unit \(i\) would have if treated
\(Y_i^0\): Potential outcome under control — the outcome unit \(i\) would have if not treated
The key insight is that both potential outcomes exist conceptually for every unit, but we can only observe one of them.
The switching equation
The observed outcome follows the switching equation:
This equation formalizes which potential outcome we observe:
If \(D_i = 1\) (treated): we observe \(Y_i = Y_i^1\)
If \(D_i = 0\) (control): we observe \(Y_i = Y_i^0\)
2. The fundamental problem of causal inference
Holland (1986) articulated what he called the fundamental problem of causal inference: we cannot observe both potential outcomes for the same unit at the same time.
Consider this example:
Unit |
Treatment |
Observed |
\(Y^1\) |
\(Y^0\) |
|---|---|---|---|---|
A |
Treated |
$500 |
$500 |
? |
B |
Control |
$300 |
? |
$300 |
C |
Treated |
$450 |
$450 |
? |
D |
Control |
$280 |
? |
$280 |
The question marks represent counterfactuals — outcomes that would have occurred under the alternative treatment assignment. These are fundamentally unobservable.
This is not a data limitation that can be solved with more observations or better measurement. It is a logical impossibility: the same unit cannot simultaneously exist in both treatment states.
3. Individual treatment effects
The individual treatment effect (ITE) for unit \(i\) is defined as:
This measures how much unit \(i\)’s outcome would change due to treatment.
Key insight: Because we can never observe both \(Y_i^1\) and \(Y_i^0\) for the same unit, individual treatment effects are fundamentally unidentifiable. This is why causal inference focuses on population-level parameters instead.
4. Population-level parameters
Since individual effects are unobservable, we focus on population averages:
Parameter |
Definition |
Interpretation |
|---|---|---|
ATE |
\(E[Y^1 - Y^0]\) |
Average effect across all units |
ATT |
\(E[Y^1 - Y^0 \mid D=1]\) |
Average effect among units that were treated |
ATC |
\(E[Y^1 - Y^0 \mid D=0]\) |
Average effect among units that were not treated |
When do these differ?
If treatment effects are homogeneous (same for everyone), then \(\text{ATE} = \text{ATT} = \text{ATC}\).
If treatment effects are heterogeneous and correlated with treatment selection, these parameters will differ. For example, if high-ability workers are more likely to get job training and benefit more from it, then \(\text{ATT} > \text{ATE}\).
5. The naive estimator and selection bias
The most intuitive approach to estimating causal effects is the naive estimator (also called the simple difference in means):
This compares average outcomes between treated and control groups. When does this equal the ATE?
Decomposing the naive estimator
We can decompose the naive estimator as follows:
The naive estimator equals the ATE only when selection bias is zero.
What causes selection bias?
Selection bias occurs when treatment assignment is correlated with potential outcomes:
This happens when treated units would have had different outcomes than control units even without treatment.
Full bias decomposition (with heterogeneous effects)
When treatment effects vary across units, the full decomposition is:
Baseline bias: Treated units have different baseline outcomes
Differential treatment effect bias: Treated units have different treatment effects
6. Randomization: the gold standard
Randomized controlled trials (RCTs) solve the selection bias problem by ensuring treatment is assigned independently of potential outcomes.
Independence assumption
Under randomization:
This means potential outcomes are statistically independent of treatment assignment.
Why randomization works
Under independence:
Therefore:
The naive estimator becomes unbiased under randomization.
7. SUTVA: stable unit treatment value assumption
The potential outcome framework relies on a critical assumption called SUTVA, which has two components:
1. No interference
One unit’s treatment assignment does not affect another unit’s potential outcomes:
Violations:
Vaccine trials: Your vaccination protects others (herd immunity)
Classroom interventions: Tutoring one student may help their study partners
Market interventions: Promoting one product may cannibalize another
Part II: Application
In Part I we defined the potential outcome framework: individual treatment effects \(\delta_i = Y_i^1 - Y_i^0\), population parameters (ATE, ATT, ATC), and the decomposition showing how selection bias corrupts the naive estimator. We also saw that randomization eliminates selection bias by making treatment independent of potential outcomes.
In this application, the simulator gives us an omniscient view — we observe both potential outcomes for every product. This lets us compute true treatment effects, verify the bias decomposition numerically, and demonstrate that randomization recovers the truth.
[1]:
# Standard library
import inspect
# Third-party packages
import numpy as np
import pandas as pd
from IPython.display import Code
from online_retail_simulator import simulate, load_job_results
from online_retail_simulator.enrich import enrich
from online_retail_simulator.enrich.enrichment_library import quantity_boost
# Local imports
from support import (
create_confounded_treatment,
generate_quality_score,
plot_balance_check,
plot_individual_effects_distribution,
plot_randomization_comparison,
plot_sample_size_convergence,
print_bias_decomposition,
print_ite_summary,
print_naive_estimator,
)
# Reproducible random number generator for Monte Carlo simulations
rng = np.random.default_rng(42)
1. Business context
What would be the effect on sales if we improved product content quality?
An e-commerce company is considering investing in content optimization (better descriptions, images, etc.) for its product catalog. Before rolling this out to all products, they want to understand the causal effect of content optimization on revenue.
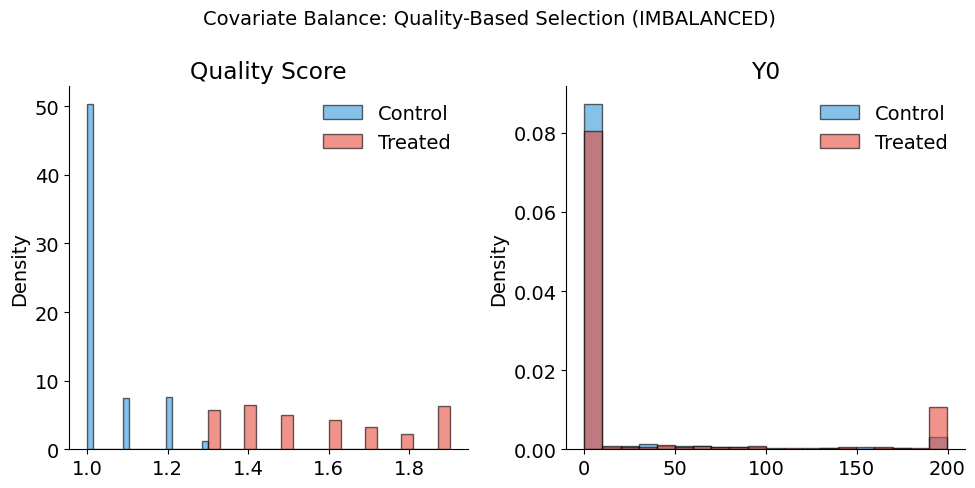
The challenge is a selection paradox: the company targets the weakest products for optimization — a sensible business decision — but this strategic selection makes the treated group look worse than the control group even before any treatment, confounding the naive comparison.
In our simulation:
Variable |
Notation |
Description |
|---|---|---|
Treatment |
\(D=1\) |
Product receives content optimization |
Control |
\(D=0\) |
Product keeps original content |
Outcome |
\(Y\) |
Product revenue |
The assignment mechanism
We simulate 5,000 products with a single day of sales data. The simulation produces baseline metrics, from which we derive a quality score and assign treatment. The company selects the lowest-quality 30% of products for content optimization — a realistic business decision to invest where the need is greatest. This strategic selection creates confounding: treated products already had lower baseline revenue before any optimization.
[2]:
!cat "config_simulation.yaml"
STORAGE:
PATH: output
RULE:
PRODUCTS:
FUNCTION: simulate_products_rule_based
PARAMS:
num_products: 5000
seed: 42
METRICS:
FUNCTION: simulate_metrics_rule_based
PARAMS:
date_start: "2024-11-15"
date_end: "2024-11-15"
sale_prob: 0.7
seed: 42
PRODUCT_DETAILS:
FUNCTION: simulate_product_details_mock
[3]:
# Run simulation and load baseline metrics
job_info = simulate("config_simulation.yaml")
metrics = load_job_results(job_info)["metrics"]
print(f"Metrics records: {len(metrics)}")
print(f"Unique products: {metrics['product_identifier'].nunique()}")
Metrics records: 5000
Unique products: 5000
[4]:
Code(inspect.getsource(create_confounded_treatment), language="python")
[4]:
def create_confounded_treatment(metrics_df, treatment_fraction=0.3, true_effect=0.5, seed=42):
"""
Create confounded treatment assignment from raw simulator metrics.
Aggregates revenue per product, generates a quality score, then assigns
treatment deterministically to the lowest-quality products (struggling
products get optimized). This creates negative selection bias: treated
products have lower baseline revenue.
Parameters
----------
metrics_df : pandas.DataFrame
Metrics DataFrame with ``product_identifier`` and ``revenue`` columns.
treatment_fraction : float, optional
Fraction of products to treat (selected from the bottom by quality).
true_effect : float, optional
True causal effect of treatment (proportional increase in revenue).
seed : int, optional
Random seed for reproducibility.
Returns
-------
pandas.DataFrame
DataFrame with columns ``product_identifier``, ``quality_score``,
``D``, ``Y0``, ``Y1``, ``Y_observed``.
"""
product_revenue = metrics_df.groupby("product_identifier")["revenue"].sum().reset_index()
product_revenue.columns = ["product_identifier", "baseline_revenue"]
product_revenue["quality_score"] = generate_quality_score(product_revenue["baseline_revenue"], seed=seed)
# Treat bottom fraction by quality (struggling products get optimized)
n_treat = int(len(product_revenue) * treatment_fraction)
treated_ids = set(product_revenue.nsmallest(n_treat, "quality_score")["product_identifier"])
product_revenue["D"] = product_revenue["product_identifier"].isin(treated_ids).astype(int)
# Potential outcomes
product_revenue["Y0"] = product_revenue["baseline_revenue"]
product_revenue["Y1"] = product_revenue["baseline_revenue"] * (1 + true_effect)
product_revenue["Y_observed"] = np.where(product_revenue["D"] == 1, product_revenue["Y1"], product_revenue["Y0"])
return product_revenue[["product_identifier", "quality_score", "D", "Y0", "Y1", "Y_observed"]]
[5]:
# Apply the confounded treatment assignment
TRUE_EFFECT = 0.5 # 50% revenue boost from content optimization
confounded_products = create_confounded_treatment(
metrics,
treatment_fraction=0.3,
true_effect=TRUE_EFFECT,
seed=42,
)
print(f"Products: {len(confounded_products)}")
print(f"Treated: {confounded_products['D'].sum()} ({confounded_products['D'].mean():.1%})")
print(f"Control: {(1 - confounded_products['D']).sum():.0f} ({1 - confounded_products['D'].mean():.1%})")
Products: 5000
Treated: 1500 (30.0%)
Control: 3500 (70.0%)
3. Naive comparison
A naive analyst — one who does not know (or ignores) the assignment mechanism — would simply compare mean outcomes across groups.
[6]:
# Naive comparison: E[Y|D=1] - E[Y|D=0]
treated = confounded_products[confounded_products["D"] == 1]
control = confounded_products[confounded_products["D"] == 0]
naive_estimate = treated["Y_observed"].mean() - control["Y_observed"].mean()
# We have the potential outcomes, so compute the true ATE
confounded_products["delta"] = confounded_products["Y1"] - confounded_products["Y0"]
ATE_true = confounded_products["delta"].mean()
print_naive_estimator(
treated["Y_observed"].mean(),
control["Y_observed"].mean(),
ATE_true,
title="Naive Estimator (Quality-Based Selection)",
)
print("\nThe naive estimator is BIASED under non-random selection!")
Naive Estimator (Quality-Based Selection):
E[Y | D=1] = $21.90
E[Y | D=0] = $56.77
Naive estimate = $-34.86
True ATE = $22.06
Bias = $-56.92
The naive estimator is BIASED under non-random selection!
Why does the naive estimate fail?
The naive estimate is biased because the assignment mechanism selected struggling products for treatment. Products with low quality scores have lower baseline revenue, so the treated group’s mean outcome is pulled down even before any treatment effect kicks in.
This is negative selection bias: the company targeted the weakest products, and their lower baseline revenue masks the positive treatment effect. In Part I’s decomposition:
The selection bias term is negative because \(E[Y^0 \mid D=1] < E[Y^0 \mid D=0]\) — treated products would have earned less even without treatment.
4. The simulator’s advantage — known potential outcomes
Unlike real data, our simulator gives us both potential outcomes for every product. This omniscient view lets us:
Compute true individual treatment effects
Calculate true population parameters (ATE, ATT, ATC)
Numerically verify the bias decomposition from Part I
The fundamental problem in practice
In real data, we observe only one potential outcome per product. The question marks below represent counterfactuals — outcomes that are fundamentally unobservable:
[7]:
# What we would OBSERVE in real data — only one potential outcome per product
fundamental_df = confounded_products[confounded_products["Y_observed"] > 0].sample(8, random_state=42).copy()
fundamental_df["Y1_obs"] = np.where(fundamental_df["D"] == 1, fundamental_df["Y1"], np.nan)
fundamental_df["Y0_obs"] = np.where(fundamental_df["D"] == 0, fundamental_df["Y0"], np.nan)
fundamental_df[["product_identifier", "D", "Y_observed", "Y1_obs", "Y0_obs"]].rename(
columns={
"product_identifier": "Product",
"Y_observed": "Observed (Y)",
"Y1_obs": "Y(1)",
"Y0_obs": "Y(0)",
}
)
[7]:
| Product | D | Observed (Y) | Y(1) | Y(0) | |
|---|---|---|---|---|---|
| 3405 | BOGV2FSI0U | 0 | 13.130 | NaN | 13.13 |
| 548 | B41GZU5WSS | 0 | 96.820 | NaN | 96.82 |
| 502 | B3PBY1KMIO | 0 | 611.740 | NaN | 611.74 |
| 1491 | BAQF63FYLC | 0 | 1340.030 | NaN | 1340.03 |
| 2122 | BF9LCGODBX | 0 | 622.680 | NaN | 622.68 |
| 2157 | BFH2MH88RK | 1 | 177.645 | 177.645 | NaN |
| 1724 | BCC4SEEZWO | 0 | 89.180 | NaN | 89.18 |
| 2139 | BFBXFJW2ER | 0 | 40.130 | NaN | 40.13 |
Full information view
The simulator knows both potential outcomes. We can see what each product would have earned under the alternative assignment:
[8]:
# Full information: both potential outcomes are known
full_info_sample = confounded_products[confounded_products["Y0"] > 0].sample(8, random_state=42)
full_info_sample[["product_identifier", "D", "Y_observed", "Y0", "Y1"]].rename(
columns={"product_identifier": "Product", "Y_observed": "Observed (Y)"}
)
[8]:
| Product | D | Observed (Y) | Y0 | Y1 | |
|---|---|---|---|---|---|
| 3405 | BOGV2FSI0U | 0 | 13.130 | 13.13 | 19.695 |
| 548 | B41GZU5WSS | 0 | 96.820 | 96.82 | 145.230 |
| 502 | B3PBY1KMIO | 0 | 611.740 | 611.74 | 917.610 |
| 1491 | BAQF63FYLC | 0 | 1340.030 | 1340.03 | 2010.045 |
| 2122 | BF9LCGODBX | 0 | 622.680 | 622.68 | 934.020 |
| 2157 | BFH2MH88RK | 1 | 177.645 | 118.43 | 177.645 |
| 1724 | BCC4SEEZWO | 0 | 89.180 | 89.18 | 133.770 |
| 2139 | BFBXFJW2ER | 0 | 40.130 | 40.13 | 60.195 |
Individual treatment effects
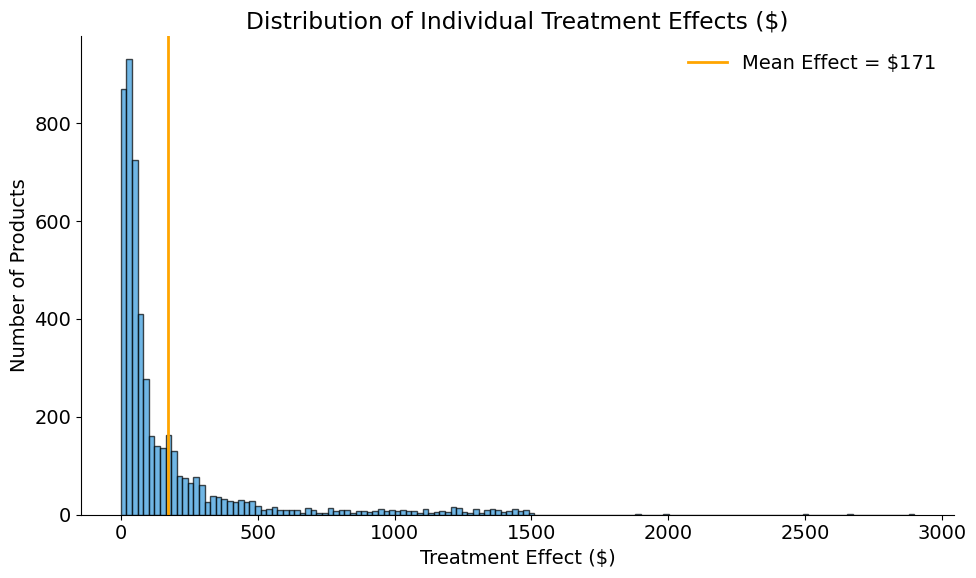
Because we have both potential outcomes, we can compute true individual treatment effects \(\delta_i = Y_i^1 - Y_i^0\):
[9]:
# Individual treatment effects: delta_i = Y^1_i - Y^0_i
print_ite_summary(confounded_products["delta"])
Individual Treatment Effects:
Mean: $22.06
Std: $117.96
Min: $0.00
Max: $2,115.80
[10]:
plot_individual_effects_distribution(
confounded_products["delta"],
title="Distribution of Individual Treatment Effects ($)",
)
True population parameters
[11]:
# True ATE, ATT, ATC (we know both potential outcomes for all units)
ATT_true = confounded_products[confounded_products["D"] == 1]["delta"].mean()
ATC_true = confounded_products[confounded_products["D"] == 0]["delta"].mean()
print(f"True ATE: ${ATE_true:,.2f}")
print(f"True ATT: ${ATT_true:,.2f}")
print(f"True ATC: ${ATC_true:,.2f}")
True ATE: $22.06
True ATT: $7.30
True ATC: $28.38
Verifying the bias decomposition
In Part I we derived that the naive estimator decomposes as:
Because the simulator gives us \(Y^0\) and \(\delta\) for every product, we can verify this decomposition numerically:
[12]:
# Baseline bias: E[Y^0 | D=1] - E[Y^0 | D=0]
baseline_treated = confounded_products[confounded_products["D"] == 1]["Y0"].mean()
baseline_control = confounded_products[confounded_products["D"] == 0]["Y0"].mean()
baseline_bias = baseline_treated - baseline_control
# Differential treatment effect bias: E[delta | D=1] - E[delta]
differential_effect_bias = ATT_true - ATE_true
print_bias_decomposition(baseline_bias, differential_effect_bias, naive_estimate, ATE_true)
Bias Decomposition:
Baseline bias: $-42.16 (treated have higher Y0)
Differential treatment effect: $-14.76
────────────────────────────────────────
Total bias: $-56.92
Actual bias (Naive - ATE): $-56.92
5. Randomization recovers the truth
In Part I we showed that under randomization, \((Y^1, Y^0) \perp\!\!\!\perp D\), which eliminates selection bias and makes the naive estimator unbiased. We now demonstrate this by using the simulator’s enrichment pipeline to assign treatment randomly to 30% of products.
Treatment effect configuration
The enrichment pipeline applies a quantity_boost to randomly selected products:
[13]:
!cat "config_enrichment_random.yaml"
IMPACT:
FUNCTION: quantity_boost
PARAMS:
effect_size: 0.5
enrichment_fraction: 0.3
enrichment_start: "2024-11-15"
seed: 42
[14]:
Code(inspect.getsource(quantity_boost), language="python")
[14]:
def quantity_boost(metrics: list, **kwargs) -> tuple:
"""
Boost ordered units by a percentage for enriched products.
Args:
metrics: List of metric record dictionaries
**kwargs: Parameters including:
- effect_size: Percentage increase in ordered units (default: 0.5 for 50% boost)
- enrichment_fraction: Fraction of products to enrich (default: 0.3)
- enrichment_start: Start date of enrichment (default: "2024-11-15")
- seed: Random seed for product selection (default: 42)
- min_units: Minimum units for enriched products with zero sales (default: 1)
Returns:
Tuple of (treated_metrics, potential_outcomes_df):
- treated_metrics: List of modified metric dictionaries with treatment applied
- potential_outcomes_df: DataFrame with Y0_revenue and Y1_revenue for all products
"""
effect_size = kwargs.get("effect_size", 0.5)
enrichment_fraction = kwargs.get("enrichment_fraction", 0.3)
enrichment_start = kwargs.get("enrichment_start", "2024-11-15")
seed = kwargs.get("seed", 42)
min_units = kwargs.get("min_units", 1)
rng = np.random.default_rng(seed)
unique_products = sorted(set(record["product_id"] for record in metrics))
n_enriched = int(len(unique_products) * enrichment_fraction)
enriched_product_ids = set(rng.choice(unique_products, size=n_enriched, replace=False))
treated_metrics = []
potential_outcomes = {} # {(product_id, date): {'Y0_revenue': x, 'Y1_revenue': y}}
start_date = datetime.strptime(enrichment_start, "%Y-%m-%d")
for record in metrics:
record_copy = copy.deepcopy(record)
product_id = record_copy["product_id"]
record_date_str = record_copy["date"]
record_date = datetime.strptime(record_date_str, "%Y-%m-%d")
is_enriched = product_id in enriched_product_ids
record_copy["enriched"] = is_enriched
# Calculate Y(0) - baseline revenue (no treatment)
y0_revenue = record_copy["revenue"]
# Calculate Y(1) - revenue if treated (for ALL products)
unit_price = record_copy.get("unit_price", record_copy.get("price"))
if record_date >= start_date:
original_quantity = record_copy["ordered_units"]
boosted_quantity = int(original_quantity * (1 + effect_size))
boosted_quantity = max(min_units, boosted_quantity)
y1_revenue = round(boosted_quantity * unit_price, 2)
else:
# Before treatment start, Y(1) = Y(0)
y1_revenue = y0_revenue
# Store potential outcomes for ALL products
key = (product_id, record_date_str)
potential_outcomes[key] = {"Y0_revenue": y0_revenue, "Y1_revenue": y1_revenue}
# Apply factual outcome (only for treated products)
if is_enriched and record_date >= start_date:
record_copy["ordered_units"] = boosted_quantity
record_copy["revenue"] = y1_revenue
treated_metrics.append(record_copy)
# Build potential outcomes DataFrame
potential_outcomes_df = pd.DataFrame(
[
{
"product_identifier": pid,
"date": d,
"Y0_revenue": v["Y0_revenue"],
"Y1_revenue": v["Y1_revenue"],
}
for (pid, d), v in potential_outcomes.items()
]
)
return treated_metrics, potential_outcomes_df
[15]:
# Apply random treatment using enrichment pipeline
enrich("config_enrichment_random.yaml", job_info)
results = load_job_results(job_info)
products = results["products"]
metrics_enriched = results["enriched"]
potential_outcomes = results["potential_outcomes"]
# Build full information DataFrame
full_info_df = potential_outcomes.merge(
metrics_enriched[["product_identifier", "enriched", "revenue"]],
on="product_identifier",
)
full_info_df = full_info_df.rename(
columns={"Y0_revenue": "Y0", "Y1_revenue": "Y1", "enriched": "Treated", "revenue": "Observed"}
)
full_info_df["delta"] = full_info_df["Y1"] - full_info_df["Y0"]
print(f"Baseline revenue: ${results['metrics']['revenue'].sum():,.0f}")
print(f"Enriched revenue: ${metrics_enriched['revenue'].sum():,.0f}")
Baseline revenue: $220,582
Enriched revenue: $480,412
[16]:
# Naive estimator under random assignment
treated_random = full_info_df[full_info_df["Treated"]]
control_random = full_info_df[~full_info_df["Treated"]]
ATE_true_random = full_info_df["delta"].mean()
print_naive_estimator(
treated_random["Observed"].mean(),
control_random["Observed"].mean(),
ATE_true_random,
title="Naive Estimator (Random Assignment)",
)
Naive Estimator (Random Assignment):
E[Y | D=1] = $215.17
E[Y | D=0] = $45.04
Naive estimate = $170.13
True ATE = $174.84
Bias = $-4.71
Covariate balance under randomization
Under random assignment, the distribution of covariates should be similar across treatment and control groups. Let’s verify this by adding a quality score and checking balance:
[17]:
Code(inspect.getsource(generate_quality_score), language="python")
[17]:
def generate_quality_score(revenue, seed=42, noise_std=0.5):
"""
Generate quality score correlated with revenue.
Higher revenue products get higher quality scores (realistic assumption:
good content quality drives higher sales).
Parameters
----------
revenue : pandas.Series or numpy.ndarray
Baseline revenue values.
seed : int, optional
Random seed for reproducibility. Default is 42.
noise_std : float, optional
Standard deviation of noise. Default is 0.5.
Returns
-------
numpy.ndarray
Quality scores in range [1, 5].
"""
rng = np.random.default_rng(seed)
# Normalize revenue to 0-1 range
revenue_min = revenue.min()
revenue_max = revenue.max()
revenue_normalized = (revenue - revenue_min) / (revenue_max - revenue_min + 1e-6)
# Map to 1-5 scale with noise
quality = 1 + 4 * revenue_normalized + rng.normal(0, noise_std, len(revenue))
return np.clip(quality, 1, 5).round(1)
[18]:
# Add quality score and check balance under random assignment
full_info_df["quality_score"] = generate_quality_score(full_info_df["Y0"])
full_info_df["D_random"] = full_info_df["Treated"].astype(int)
plot_balance_check(
full_info_df,
covariates=["quality_score", "Y0"],
treatment_col="D_random",
title="Covariate Balance: Random Assignment (BALANCED)",
)
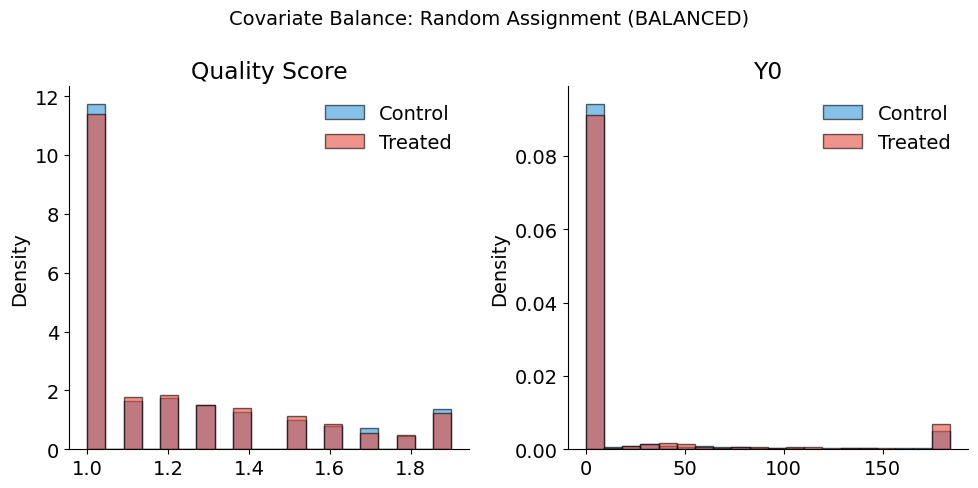
Balance Summary (Mean by Treatment Status):
--------------------------------------------------
quality_score : Control= 1.23, Treated= 1.22, Diff= -0.01
Y0 : Control= 45.04, Treated= 41.95, Diff= -3.09
6. Diagnostics & extensions
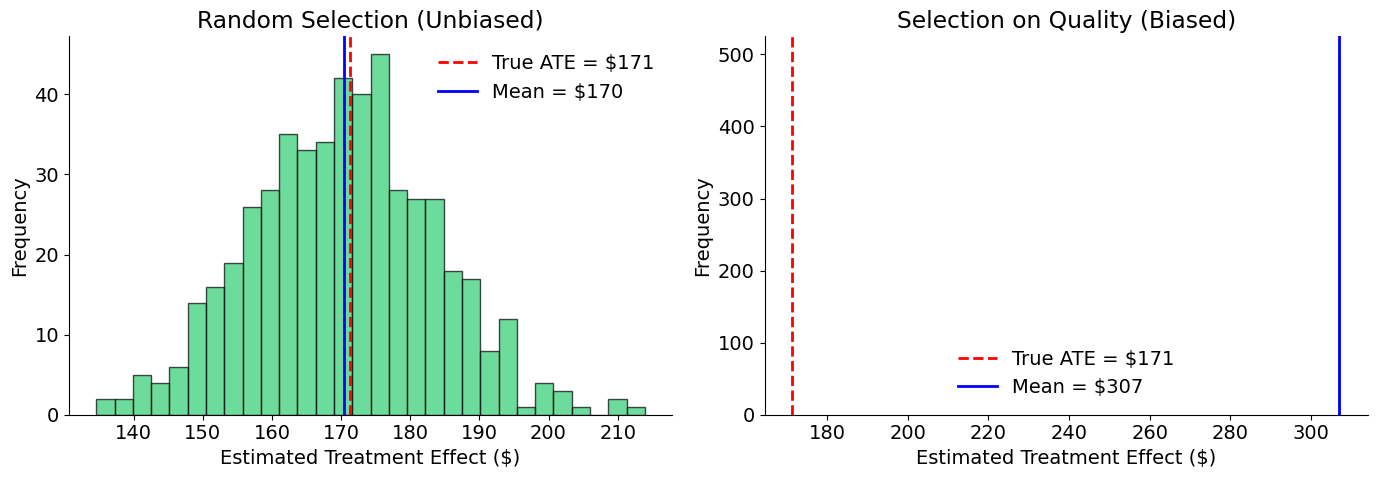
Monte Carlo: random vs. biased assignment
A single estimate may be close to the truth by luck. To demonstrate the systematic difference between random and biased selection, we run 500 simulations and compare the resulting sampling distributions:
[19]:
# Monte Carlo simulation
# 500 simulations provides stable estimates while keeping runtime reasonable (~5 seconds)
n_simulations = 500
n_treat = int(len(full_info_df) * 0.3)
random_estimates = []
biased_estimates = []
for i in range(n_simulations):
# Random selection
random_idx = rng.choice(len(full_info_df), n_treat, replace=False)
D_random = np.zeros(len(full_info_df))
D_random[random_idx] = 1
Y_random = np.where(D_random == 1, full_info_df["Y1"], full_info_df["Y0"])
est_random = Y_random[D_random == 1].mean() - Y_random[D_random == 0].mean()
random_estimates.append(est_random)
# Quality-based selection (always picks lowest quality)
bottom_idx = full_info_df.nsmallest(n_treat, "quality_score").index
D_biased = np.zeros(len(full_info_df))
D_biased[bottom_idx] = 1
Y_biased = np.where(D_biased == 1, full_info_df["Y1"], full_info_df["Y0"])
est_biased = Y_biased[D_biased == 1].mean() - Y_biased[D_biased == 0].mean()
biased_estimates.append(est_biased)
print(f"Random selection: Mean = ${np.mean(random_estimates):,.0f}, Std = ${np.std(random_estimates):,.0f}")
print(f"Quality selection: Mean = ${np.mean(biased_estimates):,.0f}, Std = ${np.std(biased_estimates):,.0f}")
print(f"True ATE: ${ATE_true_random:,.0f}")
Random selection: Mean = $175, Std = $10
Quality selection: Mean = $123, Std = $0
True ATE: $175
[20]:
plot_randomization_comparison(random_estimates, biased_estimates, ATE_true_random)
Uncertainty decreases with sample size
Under random assignment, the naive estimator is unbiased — it is centered on the true ATE. However, any single estimate will differ from the true value due to sampling variability.
The standard error of the difference-in-means estimator decreases at rate \(1/\sqrt{n}\):
This means quadrupling the sample size cuts uncertainty in half.
[21]:
# Simulate at different sample sizes
sample_sizes = [50, 100, 200, 500]
n_simulations = 500
estimates_by_size = {}
for n in sample_sizes:
estimates = []
for _ in range(n_simulations):
# Random sample of n products
sample_idx = rng.choice(len(full_info_df), n, replace=False)
sample = full_info_df.iloc[sample_idx]
# Random treatment assignment (50% treated)
n_treat_ss = n // 2
treat_idx = rng.choice(n, n_treat_ss, replace=False)
D = np.zeros(n)
D[treat_idx] = 1
# Observed outcomes under random assignment
Y = np.where(D == 1, sample["Y1"].values, sample["Y0"].values)
# Naive estimate
est = Y[D == 1].mean() - Y[D == 0].mean()
estimates.append(est)
estimates_by_size[n] = estimates
# Print summary
print("Standard Deviation by Sample Size:")
for n in sample_sizes:
std = np.std(estimates_by_size[n])
print(f" n = {n:3d}: ${std:,.0f}")
Standard Deviation by Sample Size:
n = 50: $95
n = 100: $67
n = 200: $46
n = 500: $29
[22]:
plot_sample_size_convergence(sample_sizes, estimates_by_size, ATE_true_random)
SUTVA considerations for e-commerce
Our simulation assumes SUTVA holds. In real e-commerce settings, we should consider:
Violation |
Example |
Implication |
|---|---|---|
Cannibalization |
Better content on Product A steals sales from Product B |
Interference between products |
Market saturation |
If ALL products are optimized, relative advantage disappears |
Effect depends on treatment prevalence |
Budget constraints |
Shoppers have fixed budgets; more on A means less on B |
Zero-sum dynamics |
Search ranking effects |
Optimized products rank higher, displacing others |
Competitive interference |
Additional resources
Athey, S. & Imbens, G. W. (2017). The econometrics of randomized experiments. In Handbook of Economic Field Experiments (Vol. 1, pp. 73-140). Elsevier.
Frölich, M. & Sperlich, S. (2019). Impact Evaluation: Treatment Effects and Causal Analysis. Cambridge University Press.
Heckman, J. J., Urzua, S. & Vytlacil, E. (2006). Understanding instrumental variables in models with essential heterogeneity. Review of Economics and Statistics, 88(3), 389-432.
Holland, P. W. (1986). Statistics and causal inference. Journal of the American Statistical Association, 81(396), 945-960.
Imbens, G. W. (2020). Potential outcome and directed acyclic graph approaches to causality: Relevance for empirical practice in economics. Journal of Economic Literature, 58(4), 1129-1179.
Imbens, G. W. & Rubin, D. B. (2015). Causal Inference in Statistics, Social, and Biomedical Sciences. Cambridge University Press.
Rosenbaum, P. R. (2002). Overt bias in observational studies. In Observational Studies (pp. 71-104). Springer.