Download the notebook here!
Interactive online version: ![]()
Metrics Approximation
This notebook demonstrates metrics-based impact approximation via the engine’s internal response function registry.
Workflow overview
User provides
products.csvUser configures
DATA.ENRICHMENTsectionUser calls
measure_impact(config.yaml)Engine handles everything internally (adapter, enrichment, transform, model)
Initial setup
[1]:
from pathlib import Path
import pandas as pd
from impact_engine_measure import measure_impact, load_results
from impact_engine_measure.core.validation import load_config
from impact_engine_measure.core import apply_transform
from impact_engine_measure.models.factory import get_model_adapter
from online_retail_simulator import enrich, simulate
from online_retail_simulator.simulate import simulate_product_details
Step 1 — Product Catalog
In production, this would be your actual product catalog.
[2]:
output_path = Path("output/demo_metrics_approximation")
output_path.mkdir(parents=True, exist_ok=True)
catalog_job = simulate("configs/demo_metrics_approximation_catalog.yaml", job_id="catalog")
products = catalog_job.load_df("products")
print(f"Generated {len(products)} products")
print(f"Products catalog: {catalog_job.get_store().full_path('products.csv')}")
products.head()
Generated 100 products
Products catalog: /home/runner/work/tools-impact-engine-measure/tools-impact-engine-measure/docs/source/methods/output/demo_metrics_approximation/catalog/products.csv
[2]:
| product_identifier | category | price | |
|---|---|---|---|
| 0 | BYD197RKP8 | Food & Beverage | 48.90 |
| 1 | BII7C6WHPS | Food & Beverage | 15.05 |
| 2 | BSWO4IAIN5 | Health & Beauty | 53.29 |
| 3 | BOZEL8AGQR | Electronics | 407.64 |
| 4 | BLFVUQYFOR | Home & Garden | 49.31 |
Step 2 — Engine configuration
Configure the engine with the following sections.
ENRICHMENT— Quality boost parametersTRANSFORM— Prepare data for approximationMODEL—metrics_approximationwith response function
[3]:
config_path = "configs/demo_metrics_approximation.yaml"
Step 3 — Impact evaluation
A single call to measure_impact() handles everything.
Engine creates
CatalogSimulatorAdapterAdapter simulates metrics
Adapter generates
product_detailsAdapter applies enrichment (quality boost)
Transform extracts
quality_before/quality_afterMetricsApproximationAdaptercomputes impact
[4]:
job_info = measure_impact(config_path, str(output_path), job_id="results")
print(f"Job ID: {job_info.job_id}")
Job ID: results
Step 4 — Review results
[5]:
result = load_results(job_info)
data = result.impact_results["data"]
model_params = data["model_params"]
estimates = data["impact_estimates"]
summary = data["model_summary"]
print("=" * 60)
print("METRICS-BASED IMPACT APPROXIMATION RESULTS")
print("=" * 60)
print(f"\nModel Type: {result.model_type}")
print(f"Response Function: {model_params['response_function']}")
print("\n--- Aggregate Impact Estimates ---")
print(f"Total Impact: ${estimates['impact']:.2f}")
print(f"Number of Products: {summary['n_products']}")
============================================================
METRICS-BASED IMPACT APPROXIMATION RESULTS
============================================================
Model Type: metrics_approximation
Response Function: linear
--- Aggregate Impact Estimates ---
Total Impact: $3283.69
Number of Products: 100
[6]:
# Per-product data from model artifacts
per_product_df = result.model_artifacts["product_level_impacts"]
print("\n--- Per-Product Breakdown (first 10) ---")
print("-" * 60)
print(f"{'Product':<20} {'Delta Quality':<15} {'Baseline':<12} {'Impact':<12}")
print("-" * 60)
for _, p in per_product_df.head(10).iterrows():
print(f"{p['product_id']:<20} {p['delta_metric']:<15.4f} ${p['baseline_outcome']:<11.2f} ${p['impact']:<11.2f}")
print("\n" + "=" * 60)
print("Demo Complete!")
print("=" * 60)
--- Per-Product Breakdown (first 10) ---
------------------------------------------------------------
Product Delta Quality Baseline Impact
------------------------------------------------------------
B084XJV1GS 0.1620 $4507.80 $365.13
B0LNLD9QFR 0.1660 $0.00 $0.00
B0LXAFE388 0.0410 $1174.60 $24.08
B1D6XOLRIB 0.1540 $23.38 $1.80
B1FQMFQITU 0.1160 $313.98 $18.21
B1J739H8Z3 0.2020 $12.68 $1.28
B29MR36W7L 0.2180 $58.61 $6.39
B2N9CR29LF 0.0650 $144.12 $4.68
B2R3S6DHRW 0.1260 $79.52 $5.01
B2YJLTPEHO 0.1600 $52.32 $4.19
============================================================
Demo Complete!
============================================================
Step 5 — Model validation
Compare the model’s estimate against the true causal effect computed from counterfactual vs factual data.
[7]:
def calculate_true_effect(
baseline_metrics: pd.DataFrame,
enriched_metrics: pd.DataFrame,
) -> dict:
"""Calculate TRUE impact by comparing total revenue with vs without enrichment."""
baseline_total = baseline_metrics["revenue"].sum()
enriched_total = enriched_metrics["revenue"].sum()
impact = enriched_total - baseline_total
return {
"baseline_total": float(baseline_total),
"enriched_total": float(enriched_total),
"impact": float(impact),
}
[8]:
baseline_metrics = catalog_job.load_df("metrics").rename(columns={"product_identifier": "product_id"})
# Generate product details (adds quality_score to products, required before enrichment)
pd_config = {"PRODUCT_DETAILS": {"FUNCTION": "simulate_product_details_mock"}}
store = catalog_job.get_store()
store.write_yaml("product_details_config.yaml", pd_config)
catalog_job = simulate_product_details(catalog_job, store.full_path("product_details_config.yaml"))
enrich("configs/demo_metrics_approximation_enrichment.yaml", catalog_job)
enriched_metrics = catalog_job.load_df("enriched").rename(columns={"product_identifier": "product_id"})
# Add quality_score (mirrors adapter._apply_enrichment logic)
parsed = load_config(config_path)
enrichment_start = pd.to_datetime(parsed["DATA"]["ENRICHMENT"]["PARAMS"]["enrichment_start"])
products_original = catalog_job.load_df("product_details_original")
products_enriched = catalog_job.load_df("product_details_enriched")
orig_quality = products_original.set_index("product_identifier")["quality_score"].to_dict()
enr_quality = products_enriched.set_index("product_identifier")["quality_score"].to_dict()
enriched_metrics["date"] = pd.to_datetime(enriched_metrics["date"])
enriched_metrics["quality_score"] = enriched_metrics.apply(
lambda row: (
orig_quality.get(row["product_id"], 0.5)
if row["date"] < enrichment_start
else enr_quality.get(row["product_id"], 0.5)
),
axis=1,
)
print(f"Baseline records: {len(baseline_metrics)}")
print(f"Enriched records: {len(enriched_metrics)}")
Baseline records: 1400
Enriched records: 1400
[9]:
true_effect = calculate_true_effect(baseline_metrics, enriched_metrics)
true_impact = true_effect["impact"]
model_impact = estimates["impact"]
if true_impact != 0:
recovery_accuracy = (1 - abs(1 - model_impact / true_impact)) * 100
else:
recovery_accuracy = 100 if model_impact == 0 else 0
print("=" * 60)
print("TRUTH RECOVERY VALIDATION")
print("=" * 60)
print(f"True impact: ${true_impact:,.2f}")
print(f"Model estimate: ${model_impact:,.2f}")
print(f"Recovery accuracy: {max(0, recovery_accuracy):.1f}%")
print("=" * 60)
============================================================
TRUTH RECOVERY VALIDATION
============================================================
True impact: $488.02
Model estimate: $3,283.69
Recovery accuracy: 0.0%
============================================================
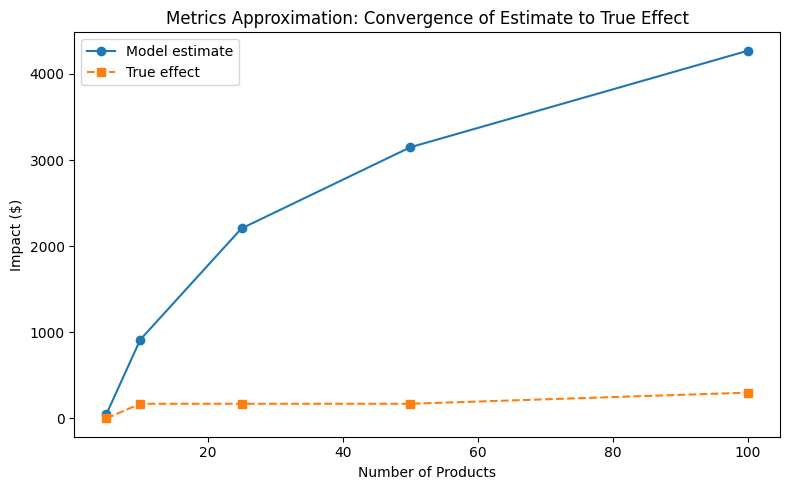
Convergence analysis
How does the estimate converge to the true effect as sample size increases?
[10]:
sample_sizes = [5, 10, 25, 50, 100]
estimates_list = []
truth_list = []
transform_config = parsed["DATA"]["TRANSFORM"]
measurement_config = parsed["MEASUREMENT"]
all_product_ids = enriched_metrics["product_id"].unique()
for n in sample_sizes:
subset_ids = all_product_ids[:n]
enriched_sub = enriched_metrics[enriched_metrics["product_id"].isin(subset_ids)]
baseline_sub = baseline_metrics[baseline_metrics["product_id"].isin(subset_ids)]
true = calculate_true_effect(baseline_sub, enriched_sub)
truth_list.append(true["impact"])
transformed = apply_transform(enriched_sub, transform_config)
model = get_model_adapter("metrics_approximation")
model.connect(measurement_config["PARAMS"])
result = model.fit(data=transformed)
estimates_list.append(result.data["impact_estimates"]["impact"])
print("Convergence analysis complete.")
Convergence analysis complete.
[11]:
from notebook_support import plot_convergence
plot_convergence(
sample_sizes,
estimates_list,
truth_list,
xlabel="Number of Products",
ylabel="Impact ($)",
title="Metrics Approximation: Convergence of Estimate to True Effect",
)