Download the notebook here!
Interactive online version: ![]()
Synthetic Control
This notebook demonstrates synthetic control impact estimation via pysyncon `Synth <https://sdfordham.github.io/pysyncon/synth.html>`__.
The synthetic control method constructs a weighted combination of control units as a counterfactual for the treated unit, then estimates the causal effect as the difference between observed and synthetic outcomes in the post-treatment period.
Workflow overview
User provides
products.csv(each product = a “unit” in the panel)User configures
DATA.ENRICHMENTfor treatment assignmentUser calls
measure_impact(config.yaml)Engine handles everything internally (adapter, enrichment, transform, model)
Initial setup
[1]:
from pathlib import Path
import pandas as pd
from impact_engine_measure import measure_impact, load_results
from impact_engine_measure.core.validation import load_config
from impact_engine_measure.core import apply_transform
from impact_engine_measure.models.factory import get_model_adapter
from online_retail_simulator import enrich, simulate
Step 1 — Product Catalog
We use a small catalog (20 products) because synthetic control treats each product as a separate unit in the donor pool.
[2]:
output_path = Path("output/demo_synthetic_control")
output_path.mkdir(parents=True, exist_ok=True)
catalog_job = simulate("configs/demo_synthetic_control_catalog.yaml", job_id="catalog")
products = catalog_job.load_df("products")
print(f"Generated {len(products)} products")
print(f"Products catalog: {catalog_job.get_store().full_path('products.csv')}")
products.head()
Generated 20 products
Products catalog: /home/runner/work/tools-impact-engine-measure/tools-impact-engine-measure/docs/source/methods/output/demo_synthetic_control/catalog/products.csv
[2]:
| product_identifier | category | price | |
|---|---|---|---|
| 0 | B1P4DZHDS9 | Electronics | 686.37 |
| 1 | B1SE4QSNG7 | Toys & Games | 80.75 |
| 2 | BXTPQIDT5C | Food & Beverage | 42.02 |
| 3 | B3F1ZMC8Q6 | Food & Beverage | 33.42 |
| 4 | B2NQRBTF0Y | Toys & Games | 27.52 |
Step 2 — Engine configuration
Configure the engine with the following sections.
ENRICHMENT— Quality boost applied to ~10% of products starting Nov 15TRANSFORM—prepare_for_synthetic_controladds a time-awaretreatmentcolumnMODEL—synthetic_controlwith one designated treated unit
The panel structure is 20 products x 30 days (Nov 1–30). Enrichment starts Nov 15, giving 14 pre-treatment and 16 post-treatment periods.
With seed=42 and enrichment_fraction=0.1, product BU9XOOP3LG is the treated unit.
[3]:
config_path = "configs/demo_synthetic_control.yaml"
Step 3 — Impact evaluation
A single call to measure_impact() handles everything.
Engine creates
CatalogSimulatorAdapterAdapter simulates daily metrics (30-day panel)
Adapter applies enrichment (quality boost to treated product after Nov 15)
prepare_for_synthetic_controltransform adds thetreatmentcolumnSyntheticControlAdapterbuilds aDataprepobject and fits via pysyncon’sSynth
[4]:
job_info = measure_impact(config_path, str(output_path), job_id="results")
print(f"Job ID: {job_info.job_id}")
Job ID: results
Step 4 — Review results
[5]:
result = load_results(job_info)
data = result.impact_results["data"]
model_params = data["model_params"]
estimates = data["impact_estimates"]
summary = data["model_summary"]
print("=" * 60)
print("SYNTHETIC CONTROL RESULTS")
print("=" * 60)
print(f"\nModel Type: {result.model_type}")
print(f"Treated Unit: {model_params['treated_unit']}")
print(f"Treatment Time: {model_params['treatment_time']}")
print("\n--- Impact Estimates ---")
print(f"ATT: {estimates['att']:.4f}")
print(f"Standard Error: {estimates['se']:.4f}")
print(f"CI Lower: {estimates['ci_lower']:.4f}")
print(f"CI Upper: {estimates['ci_upper']:.4f}")
print(f"Cumulative Effect: {estimates['cumulative_effect']:.4f}")
print("\n--- Model Summary ---")
print(f"Pre-treatment periods: {summary['n_pre_periods']}")
print(f"Post-treatment periods: {summary['n_post_periods']}")
print(f"Control units: {summary['n_control_units']}")
print(f"MSPE: {summary['mspe']:.4f}")
print(f"MAE: {summary['mae']:.4f}")
print("\n--- Control Unit Weights ---")
for unit, weight in summary["weights"].items():
if weight > 0.001:
print(f" {unit}: {weight:.4f}")
print("\n" + "=" * 60)
print("Demo Complete!")
print("=" * 60)
============================================================
SYNTHETIC CONTROL RESULTS
============================================================
Model Type: synthetic_control
Treated Unit: BU9XOOP3LG
Treatment Time: 2024-11-15 00:00:00
--- Impact Estimates ---
ATT: -11.2270
Standard Error: 28.5847
CI Lower: -67.2530
CI Upper: 44.7990
Cumulative Effect: -179.6323
--- Model Summary ---
Pre-treatment periods: 14
Post-treatment periods: 16
Control units: 19
MSPE: 20932.9987
MAE: 100.6053
--- Control Unit Weights ---
B1P4DZHDS9: 0.0530
B1SE4QSNG7: 0.0491
BXTPQIDT5C: 0.0491
B3F1ZMC8Q6: 0.0491
B2NQRBTF0Y: 0.0491
B0OL6NCQ2G: 0.0491
BELIUY7PF3: 0.0491
BZ13P24N6K: 0.0491
BY3H2A222X: 0.0491
BZUQSUBFIE: 0.0491
BY4UC1UWUT: 0.0491
BUVBMP9HJO: 0.0645
B43C4K7KPX: 0.0491
BA10ZQZF6S: 0.0491
BFRQFNIKYW: 0.0491
BNMEM8N6RZ: 0.0491
BJJ2JZ2Q0J: 0.0491
BDEQZHZL3U: 0.0963
BGA1RZXPLW: 0.0491
============================================================
Demo Complete!
============================================================
Step 5 — Model validation
Compare the model’s ATT estimate against the true per-period revenue difference for the treated unit (enriched vs counterfactual).
[6]:
def calculate_true_effect(
baseline_metrics: pd.DataFrame,
enriched_metrics: pd.DataFrame,
treated_unit: str,
treatment_time: str,
) -> dict:
"""Calculate TRUE per-period effect for the treated unit."""
treatment_date = pd.Timestamp(treatment_time)
baseline_unit = baseline_metrics[
(baseline_metrics["product_id"] == treated_unit) & (pd.to_datetime(baseline_metrics["date"]) >= treatment_date)
]
enriched_unit = enriched_metrics[
(enriched_metrics["product_id"] == treated_unit) & (pd.to_datetime(enriched_metrics["date"]) >= treatment_date)
]
baseline_mean = baseline_unit["revenue"].mean()
enriched_mean = enriched_unit["revenue"].mean()
mean_effect = enriched_mean - baseline_mean
return {
"baseline_mean": float(baseline_mean),
"enriched_mean": float(enriched_mean),
"mean_effect": float(mean_effect),
}
[7]:
baseline_metrics = catalog_job.load_df("metrics").rename(columns={"product_identifier": "product_id"})
enrich("configs/demo_synthetic_control_enrichment.yaml", catalog_job)
enriched_metrics = catalog_job.load_df("enriched").rename(columns={"product_identifier": "product_id"})
print(f"Baseline records: {len(baseline_metrics)}")
print(f"Enriched records: {len(enriched_metrics)}")
Baseline records: 600
Enriched records: 600
[8]:
treated_unit = model_params["treated_unit"]
true_effect = calculate_true_effect(baseline_metrics, enriched_metrics, treated_unit, "2024-11-15")
true_me = true_effect["mean_effect"]
model_me = estimates["att"]
if true_me != 0:
recovery_accuracy = (1 - abs(1 - model_me / true_me)) * 100
else:
recovery_accuracy = 100 if model_me == 0 else 0
print("=" * 60)
print("TRUTH RECOVERY VALIDATION")
print("=" * 60)
print(f"True mean effect: {true_me:.4f}")
print(f"Model estimate: {model_me:.4f}")
print(f"Recovery accuracy: {max(0, recovery_accuracy):.1f}%")
print("=" * 60)
============================================================
TRUTH RECOVERY VALIDATION
============================================================
True mean effect: 0.0000
Model estimate: -11.2270
Recovery accuracy: 0.0%
============================================================
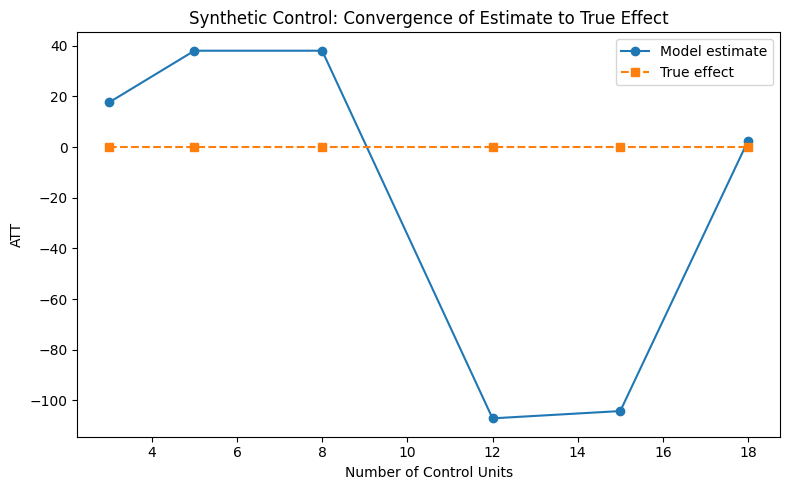
Convergence analysis
How does the estimate improve as the number of control units increases? We vary the catalog size (keeping 1 treated unit) and observe convergence.
[9]:
control_sizes = [3, 5, 8, 12, 15, 18]
estimates_list = []
truth_list = []
parsed = load_config(config_path)
measurement_params = parsed["MEASUREMENT"]["PARAMS"]
# enrichment_start is auto-injected during measure_impact() but not
# available when calling apply_transform directly — supply it explicitly.
transform_config = {
"FUNCTION": "prepare_for_synthetic_control",
"PARAMS": {"enrichment_start": "2024-11-15"},
}
# Determine which product is enriched in the retrieved metrics
# (enrichment assignment may differ from the measure_impact run).
enriched_ids = enriched_metrics[enriched_metrics["enriched"]]["product_id"].unique()
convergence_treated = enriched_ids[0]
all_ids = enriched_metrics["product_id"].unique()
control_pool = [pid for pid in all_ids if pid != convergence_treated]
for n_controls in control_sizes:
subset_ids = [convergence_treated] + control_pool[:n_controls]
enriched_sub = enriched_metrics[enriched_metrics["product_id"].isin(subset_ids)]
baseline_sub = baseline_metrics[baseline_metrics["product_id"].isin(subset_ids)]
true = calculate_true_effect(baseline_sub, enriched_sub, convergence_treated, "2024-11-15")
truth_list.append(true["mean_effect"])
transformed = apply_transform(enriched_sub, transform_config)
model = get_model_adapter("synthetic_control")
model.connect(measurement_params)
result = model.fit(
data=transformed,
treatment_time="2024-11-15",
treated_unit=convergence_treated,
outcome_column="revenue",
unit_column="product_id",
time_column="date",
)
estimates_list.append(result.data["impact_estimates"]["att"])
print("Convergence analysis complete.")
Convergence analysis complete.
[10]:
from notebook_support import plot_convergence
plot_convergence(
control_sizes,
estimates_list,
truth_list,
xlabel="Number of Control Units",
ylabel="ATT",
title="Synthetic Control: Convergence of Estimate to True Effect",
)